Using NLP to find out the core responsibilities of data science jobs.
Author
Flavia Felletti
Published
June 3, 2025
Introduction
In this post, you will find the third part of my analysis of the data science LinkedIn job postings 2024. Just a reminder, the dataset has been downloaded from Kaggle here: DataSci Job Postings 2024, and we have previously analyzed the top titles, companies and locations for data science jobs in Part I and the most in demand job skills in Part II
In this post, we use Natural Language Processing (NLP) to dive deeper into job postings and extract the core responsibilities for data science roles. Our goal is to understand the most common tasks, skills, and expectations, and to structure this information in a meaningful way. To do this, we’ll use spaCy, a powerful open-source NLP library in Python. SpaCy allows us to process and analyze large volumes of text efficiently, providing tools for tokenization, part-of-speech tagging, lemmatization, named entity recognition, and more.
We’ll begin by analyzing a single example to illustrate how spaCy works in practice, and then scale up the analysis to the full dataset of job summaries. We’ll use linguistic patterns and word frequency analysis to identify and categorize job responsibilities and visualize how they distribute across different roles. By the end, you will get some insights about the current job market which may help you in your job search or just satisfy some curiosity about the industry trends.
🗂️ Load Libraries, spaCy, and the Datasets
Before we dive into NLP, let’s load the necessary libraries and our dataset. For this analysis, we’re using two datasets:
job_postings: includes general job posting information like title, company, location, etc.
job_summary: contains the full job descriptions — the core text we’ll analyze with spaCy.
We’ll begin by importing the libraries and merging these datasets into a single DataFrame to have available the job title for each job description.
Code
# Core librariesimport pandas as pdimport numpy as np# NLP with spaCyimport spacyfrom spacy import displacy# Visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport plotly.graph_objects as goimport plotly.io as pioimport plotly.express as px# othersimport randomfrom tqdm import tqdm # makes nice progress barsfrom collections import Counterfrom collections import defaultdict
We’ll load spaCy English NLP pipeline to process our job summaries:
Code
# Load the English NLP pipelinenlp = spacy.load("en_core_web_sm")
Code
# Load datasetsjob_postings = pd.read_csv("job_postings.csv") job_summary = pd.read_csv("job_summary.csv")# Merge on 'job_link'df = pd.merge(job_postings, job_summary, on="job_link")# Keep only relevant columnsdf = df[["job_link", "job_title", "job_summary"]]# Drop rows with missing summariesdf = df.dropna()# Preview the resultdf.head(3)
job_link
job_title
job_summary
0
https://www.linkedin.com/jobs/view/senior-mach...
Senior Machine Learning Engineer
Company Description\nJobs for Humanity is part...
1
https://www.linkedin.com/jobs/view/principal-s...
Principal Software Engineer, ML Accelerators
Who We Are\nAurora (Nasdaq: AUR) is delivering...
2
https://www.linkedin.com/jobs/view/senior-etl-...
Senior ETL Data Warehouse Specialist
Location: New York City, NY\nPosition Summary\...
🧪 Exploring a Sample Job Posting with spaCy
To understand how spaCy can help us extract job responsibilities, we’ll start with one job summary and walk through the NLP pipeline. We’ll use spaCy to:
Extract noun phrases and verbs (which can reflect actions and responsibilities)
Visualize dependencies (verbs and their direct objects)
This hands-on example will give us a general idea of how spaCy parses job description text. We will use as an example the first entry of the dataset. Below you can see the job title and a part of the job description, which contains, among other things, the responsibilities.
👇 Sample Job Summary
Job Title: Senior Machine Learning Engineer Company: Capital One (via Jobs for Humanity)The job description includes various sections: company overview, diversity statement, responsibilities, and qualifications. Here’s an excerpt from the section outlining responsibilities:
As a Capital One Machine Learning Engineer (MLE), you’ll be part of an Agile team dedicated to productionizing machine learning applications and systems at scale. You’ll participate in technical design, develop and review application code, ensure high availability, and collaborate with data science teams. Responsibilities include building ML models, designing pipelines, retraining models in production, and applying best practices in Responsible AI.
We processe this description with spaCy to extract tokens, noun phrases, and verbs (lemmatized to group variations, e.g., “develops” and “developing” under “develop”).
Code
# Select title and summary of the first job of the datasetsample = df.iloc[0]sample_text = sample["job_summary"]
⛏️ Extract Relevant Text Elements
We will see now how the text can be processed with SpaCy and how we can extract tokens, noun phrases and verbs. The verbs will be lemmatized to avoid getting multiple inflections of the same verb. We’ll print the first 10 of each type.
Code
# Process the text with spaCydoc = nlp(sample_text)# Extract useful componentstokens = [token.text for token in doc]nouns = [chunk.text for chunk in doc.noun_chunks]verbs = [token.lemma_ for token in doc if token.pos_ =="VERB"]# Display a few resultsprint("Tokens:", tokens[:10])print("\nNoun Phrases:", nouns[:10])print("\nVerbs (Lemmatized):", verbs[:10])
To have a first idea of the responsibilities mentioned in the job descriptions, we can visualize the extracted verbs and their direct objects (“dobj”):
Code
# Extract verb & direct object pairsverb_obj_pairs = []for token in doc:if token.pos_ =="VERB":for child in token.children:if child.dep_ =="dobj": verb_obj_pairs.append((token.lemma_, child.text))# Show 20 random pairsfor verb, obj in random.sample(verb_obj_pairs, min(20, len(verb_obj_pairs))):print(f"{verb} → {obj}")
build → solutions
use → platforms
scale → pipelines
protect → status
ensure → availability
learn → design
recognize → frameworks
perform → activities
open → software
use → computing
promote → workplace
consider → Sections
author → paper
deploy → solutions
use → understanding
enhance → software
feed → designing
learn → more
do → What
optimize → systems
Keep in mind that not all combinations belong to the responsibiliy section of the job descriptions! Since we are using here the full description we will also have in there other sections, such as company description, benefits, and ideal candidate profile. However, we will most likely spot here some verbs that clearly indicate job responsibilities, such as “develop”, “analyze”, etc.
✅ So Far: We have now some grasp of how we can use SpaCy to process text and use it to extract relevant information from our job summaries. 👉 Next: Next, we’ll filter for responsibility sections across the dataset, extract the most frequent verbs, and categorize them into broader skill areas.
👣 Processing Steps to extract the Responsibilities Sections from the Job Descriptions
Extracting only the responsibilities from job descriptions can be tricky, as action verbs often appear in other sections too. However, we can use a few heuristics to isolate the parts most likely to contain relevant tasks. These steps also help reduce the amount of text we process with spaCy, improving performance. While these methods aren’t foolproof, they’re effective enough for our purpose.
⚠️ First Two Processing Tips:
Start from “Responsibilities”. To better isolate verbs related to job tasks, we can trim each job description from the point where a responsibilities section is likely to begin. Common section headers include:
“Responsibilities”
“What you’ll do”
“Key responsibilities”
“In this role you will”
Limit to 800–1800 characters. To avoid capturing too much from later sections (e.g., benefits, qualifications), we trim the job description to a maximum of 1800 characters starting from the responsibilities section. This window should suffice to capture the full responsibilities section.
We apply these two steps to the first three job summaries to show how they improve our input.
👣 Steps: 1. Define a List of Keywords that May Indicate the Start of the Responsibilities Section 2. Define and Apply a Function that Extracts the First 1800 Characters After the Start of the Responsibilities Section
Code
# list of likely "resposibility sections" starts:responsibility_starts = ["responsibilities","your responsibilities","what you’ll do","what you will do","what you'll be doing","your role","tasks","key duties","role summary","in this role", "as a", "you will be"]
Code
# define a function that extracts the responsibility section and the 1800 characters following its startdef extract_responsibility_1800char(text, max_len=1800): text_lower = text.lower()for phrase in responsibility_starts:if phrase in text_lower: start_idx = text_lower.find(phrase)return text[start_idx:start_idx + max_len]return text[:1800]
✂️ Trimmed Responsibility Texts – First Three Jobs:
For readability reasons, I will collapse the job summaries.
Code
# Apply to the first 3 job summaries with collapsible sectionsfor i, summary inenumerate(df["job_summary"].head(3)): extracted = extract_responsibility_1800char(summary) html =f""" <details> <summary><b>Job Summary {i+1}</b></summary> <pre>{extracted}</pre> </details> """ display(HTML(html))
Job Summary 1
What you’ll do in the role:
The MLE role overlaps with many disciplines, such as Ops, Modeling, and Data Engineering. In this role, you'll be expected to perform many ML engineering activities, including one or more of the following:
Design, build, and/or deliver ML models and components that solve real-world business problems, while working in collaboration with the Product and Data Science teams.
Inform your ML infrastructure decisions using your understanding of ML modeling techniques and issues, including choice of model, data, and feature selection, model training, hyperparameter tuning, dimensionality, bias/variance, and validation).
Solve complex problems by writing and testing application code, developing and validating ML models, and automating tests and deployment.
Collaborate as part of a cross-functional Agile team to create and enhance software that enables state-of-the-art big data and ML applications.
Retrain, maintain, and monitor models in production.
Leverage or build cloud-based architectures, technologies, and/or platforms to deliver optimized ML models at scale.
Construct optimized data pipelines to feed ML models.
Leverage continuous integration and continuous deployment best practices, including test automation and monitoring, to ensure successful deployment of ML models and application code.
Ensure all code is well-managed to reduce vulnerabilities, models are well-governed from a risk perspective, and the ML follows best practices in Responsible and Explainable AI.
Use programming languages like Python, Scala, or Java.
Basic Qualifications:
Bachelor’s degree.
At least 4 years of experience programming with Python, Scala, or Java (Internship experience does not apply)
At least 3 years of experience designing and building data-intensive solutions
Job Summary 2
In this role, you will
Work closely with our autonomy and hardware teams to understand our on-vehicle ML technology
Develop perspectives on where opportunities and gaps might be in our machine learning software and hardware strategy with a longer-term horizon in mind
Maintain relationships and intel across the ML ecosystem including both established players and start-ups (accelerators, software modules, etc.) for both existing and future products
Execute internal research and development of ML software and hardware technology
Surface high-impact findings to relevant Engineering leadership, keeping feedback loop going to influence Aurora’s ML strategy
Help drive value to key engineering stakeholders
Required Qualifications
Minimum 5+ years of professional experience
BS, MS, or PhD in Computer Science or related field
Strong programming skills in C++, Python
Familiarity with at least one deep learning framework (PyTorch, TensorFlow, MXNet, etc.)
Basic understanding of computer vision deep learning models.
Strong analytical skills, especially for performance troubleshooting (e.g. profiling, roofline model)
Familiarity with CUDA, OpenCL, OpenVX, Halide or other SIMD programming models
Familiarity with ML-specific accelerators (NPUs, TPUs, IPUs, etc…)
Ability to quickly learn and adapt to new technology
Ability to work on large code bases and a fast growing environment.
Strong communication skills
Comfortable with Linux/other unix environments
Desirable Qualifications
Experience with inference on edge platforms
Experience with cloud ML training pipelines
HPC experience
Pay Range
The base salary range for this position is $247,000 - $395,000. Aurora’s pay ranges are determined by role, level, and location. Within the range, the successful candidate’s starting base pay will be
Job Summary 3
Responsibilities
Data Integration and ETL Development:
Design, develop, and maintain scalable ETL processes for extracting, transforming, and loading data from various sources into the data warehouse.
Collaborate with cross-functional teams to understand business requirements and translate them into ETL workflows.
Data Modeling and Architecture:
Work closely with data architects to design and implement data models that support the organization's data warehousing needs.
Ensure data quality and integrity throughout the ETL process, implementing best practices for data validation and cleansing.
Performance Optimization:
Identify and implement optimizations to enhance the performance of ETL processes and ensure timely delivery of high-quality data.
Conduct thorough performance tuning and troubleshooting of ETL workflows.
Documentation and Reporting:
Create and maintain comprehensive documentation for ETL processes, data models, and workflows.
Generate reports and provide insights to stakeholders, ensuring data accuracy and relevance.
Collaboration and Communication:
Collaborate with business analysts, data scientists, and other stakeholders to understand data requirements and deliver solutions.
Communicate effectively with team members, providing technical guidance and support.
Qualifications
Bachelor's degree in Computer Science, Information Systems, or a related field.
Proven experience as an ETL Developer or Data Warehouse Specialist in the Financial/Banking domain.
Strong proficiency in ETL tools such as Informatica, Talend, or Apache NiFi.
Expertise in SQL, data modeling, and performance optimization.
Familiarity with data warehousing concepts and best practices.
Excellent problem-solving and analytical skills.
Effective communication and collaboration skills.
Preferre
⚠️ A Third Processing Tip 3. Trim at the start of the “Qualifications” section. From the previous examples, we see that the responsibilities section is often followed by a qualifications section. To further isolate the duties, we can also trim the text at the start of this next section.
👣 Steps: 1. Define a List of Keywords that May Indicate the Start of the Qualifications Section 2. Define and Apply a Function that Cuts Out the Qualifications Section 3. Combine All Three Steps into a Single Function 4. Apply the Function to the Full Dataset
✂️ Final Responsibility Sections — First 5 Job Descriptions
Code
# Apply to the first 5 summaries with collapsible sectionsfor i, summary inenumerate(df["job_summary"].head(5)): extracted = extract_responsibility_only(summary) html =f""" <details> <summary><b>Job {i+1} Responsibility Section</b></summary> <pre>{extracted}</pre> </details> """ display(HTML(html))
Job 1 Responsibility Section
What you’ll do in the role:
The MLE role overlaps with many disciplines, such as Ops, Modeling, and Data Engineering. In this role, you'll be expected to perform many ML engineering activities, including one or more of the following:
Design, build, and/or deliver ML models and components that solve real-world business problems, while working in collaboration with the Product and Data Science teams.
Inform your ML infrastructure decisions using your understanding of ML modeling techniques and issues, including choice of model, data, and feature selection, model training, hyperparameter tuning, dimensionality, bias/variance, and validation).
Solve complex problems by writing and testing application code, developing and validating ML models, and automating tests and deployment.
Collaborate as part of a cross-functional Agile team to create and enhance software that enables state-of-the-art big data and ML applications.
Retrain, maintain, and monitor models in production.
Leverage or build cloud-based architectures, technologies, and/or platforms to deliver optimized ML models at scale.
Construct optimized data pipelines to feed ML models.
Leverage continuous integration and continuous deployment best practices, including test automation and monitoring, to ensure successful deployment of ML models and application code.
Ensure all code is well-managed to reduce vulnerabilities, models are well-governed from a risk perspective, and the ML follows best practices in Responsible and Explainable AI.
Use programming languages like Python, Scala, or Java.
Basic
Job 2 Responsibility Section
In this role, you will
Work closely with our autonomy and hardware teams to understand our on-vehicle ML technology
Develop perspectives on where opportunities and gaps might be in our machine learning software and hardware strategy with a longer-term horizon in mind
Maintain relationships and intel across the ML ecosystem including both established players and start-ups (accelerators, software modules, etc.) for both existing and future products
Execute internal research and development of ML software and hardware technology
Surface high-impact findings to relevant Engineering leadership, keeping feedback loop going to influence Aurora’s ML strategy
Help drive value to key engineering stakeholders
Required
Job 3 Responsibility Section
Responsibilities
Data Integration and ETL Development:
Design, develop, and maintain scalable ETL processes for extracting, transforming, and loading data from various sources into the data warehouse.
Collaborate with cross-functional teams to understand business requirements and translate them into ETL workflows.
Data Modeling and Architecture:
Work closely with data architects to design and implement data models that support the organization's data warehousing needs.
Ensure data quality and integrity throughout the ETL process, implementing best practices for data validation and cleansing.
Performance Optimization:
Identify and implement optimizations to enhance the performance of ETL processes and ensure timely delivery of high-quality data.
Conduct thorough performance tuning and troubleshooting of ETL workflows.
Documentation and Reporting:
Create and maintain comprehensive documentation for ETL processes, data models, and workflows.
Generate reports and provide insights to stakeholders, ensuring data accuracy and relevance.
Collaboration and Communication:
Collaborate with business analysts, data scientists, and other stakeholders to understand data requirements and deliver solutions.
Communicate effectively with team members, providing technical guidance and support.
Job 4 Responsibility Section
Responsibilities:
Candidate must have significant, hands-on technical experience and expertise with data lakes, data bricks, Azure data factory pipelines, Spark, and Python.
Significant, hands-on technical experience and expertise with leading the design, implementation and maintenance of business intelligence and data warehouse solutions, with expertise in using the SQL Server and Azure.
Producing ETL/ELT using SQL Server Integration Services and other tools.
Experience with SQL Server, T-SQL, scripts, queries.
Experience with data formatting, capture, search, retrieval, extraction, classification, and information filtering techniques.
Experience with data mining architectures, modeling standards, reporting and data analysis methodologies.
Experience with data engineering, database file systems optimization, API’s, and analytics as a service.
Analyzing and translating business
Job 5 Responsibility Section
As a Capital One Lead Data Engineer, you'll have the opportunity to be on the forefront of driving a major transformation within Capital One.
On this team, we are building a suite of products to help our dealers connect with potential car buyers! This team is focusing on building the data infrastructure (right from ingestion to consumption) for all of our products from ground up. We build intelligence for scaling to more dealers and build personalized customer experience.
What You'll Do:
Collaborate with and across Agile teams to design, develop, test, implement, and support technical solutions in full-stack development tools and technologies
Work with a team of developers with deep experience in machine learning, distributed microservices, and full stack systems
Utilize programming languages like Java, Scala, Python and Open Source RDBMS and NoSQL databases and Cloud based data warehousing services such as Redshift and Snowflake
Share your passion for staying on top of tech trends, experimenting with and learning new technologies, participating in internal & external technology communities, and mentoring other members of the engineering community
Collaborate with digital product managers, and deliver robust cloud-based solutions that drive powerful experiences to help millions of Americans achieve financial empowerment
Perform unit tests and conduct reviews with other team members to make sure your code is rigorously designed, elegantly coded, and effectively tuned for performance
Basic
Code
# Create a new column for the responsibility section extracteddf["responsibility_text"] = df["job_summary"].apply(extract_responsibility_only)df.head(3)
job_link
job_title
job_summary
responsibility_text
0
https://www.linkedin.com/jobs/view/senior-mach...
Senior Machine Learning Engineer
Company Description\nJobs for Humanity is part...
What you’ll do in the role:\nThe MLE role over...
1
https://www.linkedin.com/jobs/view/principal-s...
Principal Software Engineer, ML Accelerators
Who We Are\nAurora (Nasdaq: AUR) is delivering...
In this role, you will\nWork closely with our ...
2
https://www.linkedin.com/jobs/view/senior-etl-...
Senior ETL Data Warehouse Specialist
Location: New York City, NY\nPosition Summary\...
Responsibilities\nData Integration and ETL Dev...
🧠 Processing the Full Dataset with spaCy
Now that we’ve seen how to extract verbs from a single job description, let’s scale up. In this section, we’ll extract the core responsibilities from all job descriptions in our dataset using spaCy.
Goals: - Process the responsibility_text column for all entries - Extract all lemmatized verbs - Display the most recurring action verbs - Categorize responsibilities into defined task categories - Analyze how responsibilities vary across different job roles
🛠️ Extract All Verbs with spaCy
We apply the same lemmatization pipeline to all job descriptions in the dataset. This allows us to identify which verbs most commonly describe data job responsibilities.
Code
# Process all responsibilities sections with spaCydocs =list(nlp.pipe(df["responsibility_text"]))
Code
# Collect all lemmatized verbsverb_lemmas = []for doc in docs:for token in doc:if token.pos_ =="VERB": verb_lemmas.append(token.lemma_.lower())# Count frequenciesverb_freq = Counter(verb_lemmas)
Code
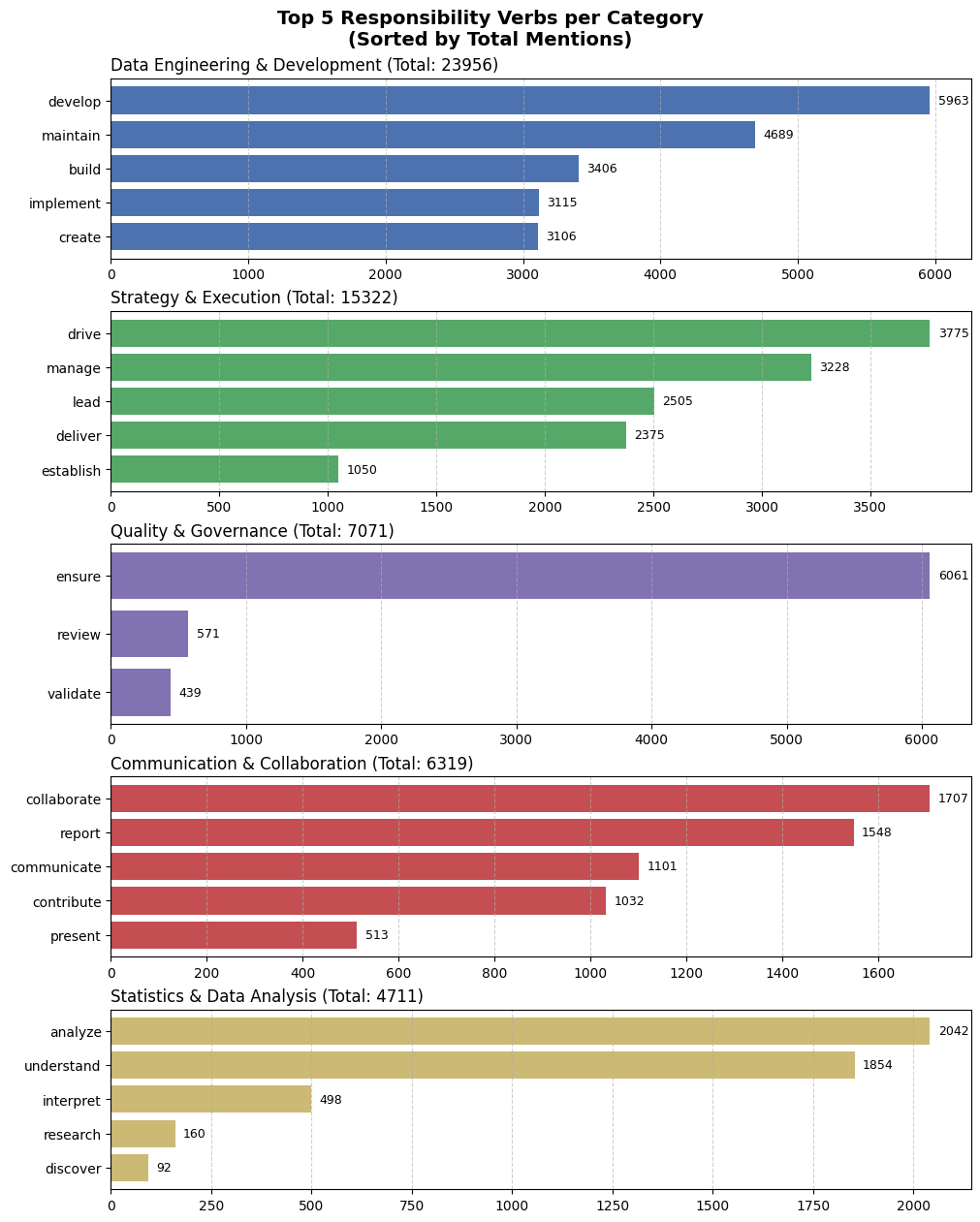
# Show 20 most common verb lemmastop_verbs = verb_freq.most_common(20)for verb, freq in top_verbs:print(f"{verb:15}{freq}")
work 7515
include 7049
ensure 6061
develop 5963
provide 5835
use 4803
maintain 4689
support 3991
drive 3775
identify 3501
show 3492
build 3406
have 3402
require 3349
perform 3255
manage 3228
implement 3115
create 3106
base 2789
need 2526
🧩 Categorize Job Responsibilities
We now group verbs into broader responsibility categories, based on common data science tasks. These categories are manually defined and are not exhaustive. Some verbs may fit in multiple categories depending on context, but we aim to capture general trends rather than perfect precision.
Responsibility Categories Example:
Data Engineering & Development: build, develop, implement
Strategy & Execution: lead, drive, align, plan
Quality & Governance: ensure, validate, audit
Communication & Collaboration: present, report, coordinate
Statistics & Data Analysis: analyze, visualize, research
We will now use our mapping to categorize the verbs and count the occurrences of each verb within its category, and we will show the top 5 skills per category. I will sort the categories to show first in the graphic the category with the highest mentions.
Code
# Categorize verbs and count occurrences within the categorycategory_freq = defaultdict(list)for verb, freq in verb_freq.items(): category = verb_categories.get(verb)if category: category_freq[category].append((verb, freq))# Sort verbs by frequency within each categoryfor cat in category_freq: category_freq[cat] =sorted(category_freq[cat], key=lambda x: x[1], reverse=True)
Code
# Define a distinct color for each categorycategory_colors = {"Data Engineering & Development": "#4C72B0","Strategy & Execution": "#55A868","Communication & Collaboration": "#C44E52","Quality & Governance": "#8172B2","Statistics & Data Analysis": "#CCB974"}# Sort by frequency per category# Compute total frequency per categorycategory_totals = {cat: sum(freq for _, freq in verbs) for cat, verbs in category_freq.items()}# Sort categories by total frequency (descending)sorted_categories =sorted(category_totals, key=category_totals.get, reverse=True)# Set up plotn_categories =len(sorted_categories)fig, axes = plt.subplots(n_categories, 1, figsize=(10, 2.5* n_categories), constrained_layout=True)# If only one category, make sure axes is iterableif n_categories ==1: axes = [axes]# Plot each categoryfor ax, category inzip(axes, sorted_categories): top_verbs = category_freq[category][:5] verbs = [v for v, _ in top_verbs] counts = [f for _, f in top_verbs] color = category_colors.get(category, 'gray') ax.barh(verbs, counts, color=color) ax.set_title(f"{category} (Total: {category_totals[category]})", fontsize=12, loc='left') ax.invert_yaxis() ax.grid(axis='x', linestyle='--', alpha=0.6)for i, v inenumerate(counts): ax.text(v +max(counts)*0.01, i, str(v), va='center', fontsize=9)fig.suptitle("Top 5 Responsibility Verbs per Category\n(Sorted by Total Mentions)", fontsize=14, fontweight='bold')plt.show()
We now know which are the top tasks required for each category. However, this per se may not be particularly informative. We will now continue our analysis focusing on individuating the top responsibilities for different roles.
🔝 Top Job Responsibilities for the Different Roles
🧪 Job Role Categorization
As we have many different job titles, we grouped job titles using keyword matching into broader roles:
Data Engineer
Machine Learning Engineer
Data Analyst
Data Architect / Manager
For simplicity, I will exclude all other jobs.
Note: I chose to exclude the Data Scientist role from the categorization below. In practice, the title Data Scientist often overlaps heavily with roles such as Data Analyst, Machine Learning Engineer, and Data Engineer. Since the keyword patterns typically used to identify Data Scientist positions appear across these other roles, reliably distinguishing it from them using a simple keyword-based approach would be error-prone and potentially misleading.
Code
# define a function to group the jobs in the above categoriesdef map_job_title(title): title_lower = title.lower()ifany(keyword in title_lower for keyword in ['data engineer', 'etl', 'data warehouse', 'database', 'dba', 'mlops']):return'Data Engineer'elifany(keyword in title_lower for keyword in ['machine learning', 'ml ', 'mlops', 'ml infrastructure']):return'Machine Learning Engineer'elifany(keyword in title_lower for keyword in ['data analyst', 'analytics', 'process analyst', 'financial analyst']):return'Data Analyst'elifany(keyword in title_lower for keyword in ['architect', 'manager', 'product owner', 'lifecycle']):return'Data Architect / Manager'else:returnNone# No category assigned
Code
# drop none valuesdf["job_role"] = df["job_title"].apply(map_job_title)df = df[df["job_role"].notna()] # Drop rows with no matching role
📊 Number of jobs per category:
Code
# add a column with the role category to our dataframedf['role_category'] = df['job_title'].apply(map_job_title)# count roles per categorycounts = df['role_category'].value_counts()# show the number of jobs per role categoryprint(counts)
role_category
Data Engineer 2749
Data Analyst 2285
Data Architect / Manager 1613
Machine Learning Engineer 1046
Name: count, dtype: int64
Code
# Extract main verbs and categorize themrole_cat_counts = defaultdict(lambda: defaultdict(int))for _, row in df.iterrows(): role = row['role_category'] doc = nlp(row['responsibility_text'])for token in doc:if token.pos_ =="VERB": lemma = token.lemma_.lower() category = verb_categories.get(lemma)if category: role_cat_counts[role][category] +=1# Convert to DataFramedf_role_cat = pd.DataFrame(role_cat_counts).fillna(0).astype(int).Tdf_role_cat = df_role_cat[sorted(df_role_cat.columns, key=lambda x: -df_role_cat[x].sum())] # sort by total importancedf_role_cat
Data Engineering & Development
Strategy & Execution
Quality & Governance
Communication & Collaboration
Statistics & Data Analysis
Machine Learning Engineer
2551
1357
618
562
269
Data Engineer
6879
3266
1269
1067
562
Data Analyst
4134
3142
1296
1813
1739
Data Architect / Manager
3418
2852
1396
792
592
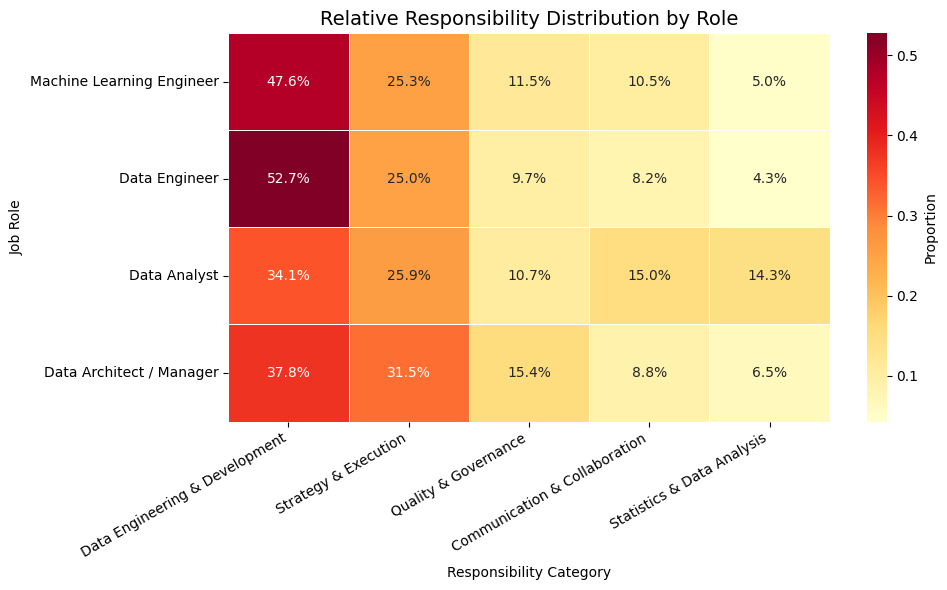
📈 Heatmap of Responsibilities by Role
To have a clearer idea of how important each responsibility is within each job role, we will normalize the data and visualize the relative discribution by role through a heatmap:
Code
# calculate relative distribution by roledf_relative = df_role_cat.div(df_role_cat.sum(axis=1), axis=0)# create heatmapplt.figure(figsize=(10, 6))sns.heatmap(df_relative, annot=True, fmt='.1%', cmap='YlOrRd', linewidths=0.5, cbar_kws={'label': 'Proportion'})plt.title('Relative Responsibility Distribution by Role', fontsize=14)plt.xlabel('Responsibility Category')plt.ylabel('Job Role')plt.xticks(rotation=30, ha='right')plt.tight_layout()plt.show()
🕸️ Radar Chart (Interactive Plot)
To provide a more intuitive overview, we can display the normalized values in an interactive radar chart using Plotly:
Code
# Set renderer for JupyterLabpio.renderers.default ='notebook'# Prepare datacategories =list(df_relative.columns)theta = categories + [categories[0]]# Generate distinct colors using Plotly Expresscolors = px.colors.qualitative.Set2color_cycle = colors * (len(df_relative) //len(colors) +1) # Repeat colors if needed# Create figurefig = go.Figure()# Add a trace for each rolefor i, (role, row) inenumerate(df_relative.iterrows()): values = row.tolist() + [row.tolist()[0]] fig.add_trace(go.Scatterpolar( r=[v *100for v in values], theta=theta, fill='toself', name=role, visible=Trueif i ==0elseFalse, line=dict(color=color_cycle[i]), fillcolor=color_cycle[i], opacity=0.5 ))# Dropdown optionsbuttons = []# “Show All” buttonbuttons.append(dict( label="Show All Roles", method="update", args=[{"visible": [True] *len(df_relative)}, {"title": "Responsibility Distribution: All Roles"}]))# One button per rolefor i, role inenumerate(df_relative.index): visibility = [j == i for j inrange(len(df_relative))] buttons.append(dict( label=role, method="update", args=[{"visible": visibility}, {"title": f"Responsibility Distribution: {role}"}] ))# Update layout with dropdown and stylingfig.update_layout( updatemenus=[dict( buttons=buttons, direction="down", showactive=True, x=1.2, xanchor="left", y=1.05, yanchor="top" )], polar=dict( radialaxis=dict( visible=True, tickvals=[10, 20, 30, 40, 50], ticktext=['10%', '20%', '30%', '40%', '50%'], tickfont=dict(size=10),range=[0, 60] ), angularaxis=dict( tickfont=dict(size=11) ) ), title="Responsibility Distribution: "+ df_relative.index[0], width=750, height=750, showlegend=True)fig.show()
Key Takeaways
Different data roles emphasize distinct areas of responsibility:
Data Engineers and Machine Learning Engineers focus heavily on Data Engineering & Development (53% and 48%, respectively), reflecting their infrastructure-related duties.
Data Analysts show a more balanced profile, with a significant focus on Statistics & Data Analysis (14%) and Communication & Collaboration (15%).
Data Architects / Managers emphasize Strategy & Execution (32%) and Quality & Governance (15%), along with their engineering duties.
Conclusions
In this analysis, we set out to extract and understand the core responsibilities associated with data-related job postings. Using spaCy for natural language processing, we lemmatized and categorized the verbs found in job descriptions, aiming to uncover common themes and tasks across different job roles.
🔍 What We Did
Processed the full dataset of job postings using spaCy to extract verbs from the responsibility_text field.
Identified the most frequently occurring verbs, giving us insight into the most common tasks mentioned in data job descriptions.
Manually grouped verbs into five functional categories representing types of responsibilities: Data Engineering & Development, Strategy & Execution, Quality & Governance, Communication & Collaboration, and Statistics & Data Analysis.
Classified job titles into four role categories: Data Engineer, Machine Learning Engineer, Data Analyst, and Data Architect / Manager.
Quantified and visualized the distribution of responsibility categories across job roles using a heatmap and an interactive radar chart.
📌 Key Findings
Data Engineers and Machine Learning Engineers are (unsurprisingly) primarily responsible for Data Engineering & Development, comprising over 50% of their tasks.
Data Analysts show a more balanced task profile, with significant focus on Statistics, Communication, and Execution.
Data Architects and Managers emphasize Strategy & Execution and Governance, reflecting their leadership and oversight roles.
⚠️ Limitations
Verb categorization was manual and subjective: Some verbs may belong to multiple categories depending on context, and nuances in responsibilities might be missed.
Simplified role classification: We used basic keyword matching, which may misclassify some jobs or overlook hybrid roles.
No context-aware disambiguation: Verbs like develop or manage may carry different meanings depending on the full sentence, which our approach does not capture.
🔄 Proposed Next Steps
Improve role classification using named entity recognition or fine-tuned language models to better identify nuanced job titles.
Use sentence-level or dependency-based parsing to better understand responsibility contexts and relationships between verbs and objects.
Extend the analysis to include qualifications, skills, and tools mentioned in job descriptions.
Compare over time or geography: Analyze how responsibilities differ by country, industry, or over the past few years to track trends in job expectations.